

这是一台完全用国产芯片建造的超级计算机,目标是跻身世界最快之列。
4月26日,深圳国家超级计算中心正式发布名为"凌星"(LineShine)的新一代超级计算机项目。按照规划,这台机器的持续算力将超过2 ExaFlops,即每秒200京次浮点运算。目前全球速度最快的超级计算机是美国的El Capitan,基于AMD处理器,峰值算力约为2.8 ExaFlops。凌星一旦建成,将直接挤入世界超算第一梯队的竞争行列。
更引人关注的,不只是这个数字,而是实现这个数字的方式:凌星的全部技术均来自国内,不依赖任何国际供应商。
47000颗CPU,和一套世界最大的液冷系统
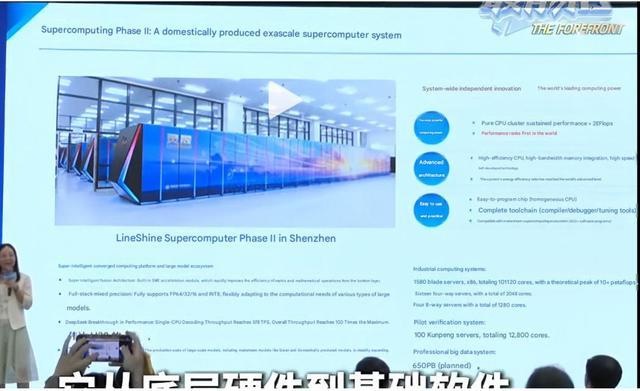
凌星项目将分两期建设。第一期验证系统基于100台华为鲲鹏服务器,共计12800个计算核心,用于测试和验证整体架构的可行性。
第二期才是真正的主体工程。届时系统将容纳92个计算机柜,搭载总计47000颗CPU,并配备36个网络机柜,具备扩展至数十万节点、百万端口互连的能力。整个工业园区的刀片服务器集群将配备x86处理器,合计超过10万个计算核心,理论峰值性能超过10 Petaflops。
这套系统在存储和散热方面的规格同样令人印象深刻。凌星计划配备650 PB的总存储容量,并将建成全球最大规模的液冷解决方案:67个液冷存储机柜,428个存储节点,系统带宽达到10 TB/s。整个冷却装置的二次管道总长度超过3200米,净重接近244吨。
从纯粹的工程角度看,这是一个极其庞大的物理系统。

在计算架构上,凌星采用Fusion架构,集成SMT加速器,支持全栈混合精度计算,覆盖FP64、FP32、FP16和INT8等多种精度模式,既能满足科学计算需求,也能支撑各类AI模型的推理和训练任务。
国产算力的战略意图
凌星的发布,很难脱离中美科技竞争的大背景来理解。
过去数年,美国对华半导体出口管控持续收紧,英伟达高端GPU受限,ASML光刻机受限,几乎所有顶级计算芯片的出口都需要经过严格审查。中国科技界被迫加速走上一条自主研发的道路,凌星正是这条路上最具代表性的里程碑之一。
值得注意的是,凌星是一个纯CPU架构的超算项目,而非依赖GPU集群。这与当前AI计算的主流路线有所不同,英伟达的H100、B200系列GPU正是当下全球AI训练任务的核心算力载体。但对于中国而言,在GPU进口渠道受阻的现实条件下,发展基于国产CPU的高性能计算体系,具有明确的战略必要性。
凌星已在DeepSeek模型测试中实现单颗CPU每秒578个token的推理吞吐量,系统整体吞吐量预计是这一数字的百倍以上。除AI推理外,该系统还将承担遥感、气象学、材料科学、生物信息学、制药研发、石油勘探、生命科学和电磁模拟等广泛的科学计算任务。
这个应用范围的设计,勾勒出中国对这台机器的定位:它不只是一台超算,而是一个面向多个战略性科研领域的基础设施平台。
从全球超算格局来看,中国长期以来在Top500榜单上保持着相当数量的上榜系统,但受制于出口管控,许多国内顶级系统近年来选择不提交TOP500测评数据,其真实算力外界难以评估。凌星的公开发布,本身就是一种信号:中国有意在超算领域重新建立可见的、有竞争力的国际存在。
目前,凌星尚无具体的投入运行时间表,外界预计最快将在2029至2030年前后全面启动。从现在到那时,超算竞赛的格局会如何演变,仍有很大的悬念。但有一点已经清晰:完全依赖进口芯片的时代,中国不打算继续等待。
宇轩配资提示:文章来自网络,不代表本站观点。
相关文章



沪深京行情 实时轮播
热点资讯
